在搜尋技術中TF-IDF是個很基礎而重要的統計方式。什麼是TF-IDF呢?而又為什麼需要TF-IDF?
TF-IDF的全名是Term Frequency - Inverted Document Frequency,大概可以翻作詞頻-倒文件頻(維基百科上面也直接寫TF-IDF)。它的統計結果能夠直觀地呈現一個詞在整個文集的某一個檔案中佔有怎麼樣的重要性。有些詞很少出現在整個文集的其他文件中,卻頻繁的出現在其中一個文件裡,那我們大概可以猜到這個字這份文件的關鍵字。另一面,有些詞(例如中文的「的、我」)頻繁的出現在文集中的每個文件裡,那麼說明這個詞並沒有什麼顯著性,因為大家都有。照著TF-IDF字面上的意思我們大略能夠明白,這個統計方法會取兩個值的乘積:
(1) 詞頻(TF),一個詞出現在一個文件的頻率或次數,其中我們想知道字詞t在文件d中的詞頻,我們就可以取分子 - t出現在d中的次數(frequency)以及分母 - 所有字詞出現在d的次數(也就是文件長度)。例如某篇文章總共有100個字詞,如果我們想知道rock在這個文章中的詞頻,而rock總共出現了3次,那麼詞頻就會是 (3/100 = 0.03)。
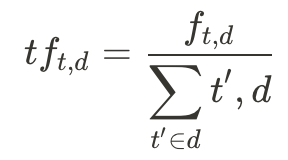
(2) 倒文件頻(IDF),所有文件中含有這個詞之數量的倒數;實務上通常會取一個log。倒數前的document frequency(也就d_t / D)中,分子計算了包含文件中出現過字詞t的文件數量,分母則是所有文件的總數;將其倒數後就成了idf。舉例來說,整個文集裡面有10篇文章,其中出現rock這個詞的文中有2篇,那麼df就是 (2/10 = 0.2),而未取log前的idf就是 (10/2 = 5)。
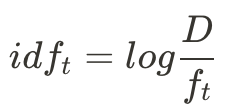 ,其中
,其中 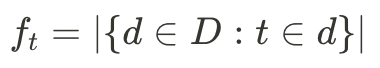
我們再根據昨天下載和預處理過的資料,以及寫好的倒排索引來實作TF-IDF:
我們現在根據Day 9中開發的 InvertedIndex 類別來計算文件和查詢Q之間的TF-IDF相似度。
在這裡,我們使用簡易版的TF-IDF相似度計算公式:
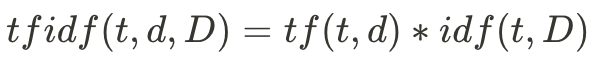
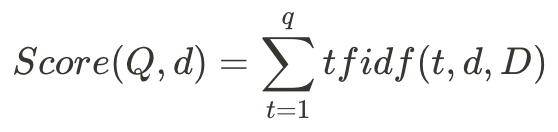
其中Q指的是我們的查詢,包含了多個查詢字q。這些資料都是我們在 InvertedIndex 類別中預先存好的。我們再繼續用剛剛rock的例子:假如我們的查詢中只包含一個字rock,那麼我們的tfidf值就是 tfidf = 0.03 * log(5) = 0.03 * 0.7 = 0.021。這個數字可以說明rock這個詞在這份文件中並不顯著。若在查詢中有多個詞的話,我們會把每個字詞的tfidf加總作為分數。
我們的 query_tfidf function中輸入一句查詢以及一個索引類別,最後回傳 top-k TF-IDF分數最高的文件。
from math import log, sqrt
# 給定一個查詢(String)和一個索引(Class),回傳k個文件
def query_tfidf(query, index, k=10):
# scores 儲存了docID和他們的TF-IDF分數
scores = Counter()
N = index.num_docs()
for term in query:
i = 0
f_t = index.f_t(term)
for docid in index.docids(term):
# f_(d,t)
f_d_t = index.freqs(term)[i]
d = index.doc_len[docid]
tfidf_cal = log(1+f_d_t) * log(N/f_t) / sqrt(d)
scores[docid] += tfidf_cal
i += 1
return scores.most_common(k)
# 查詢語句
query = "south korea production"
# 預處理查詢,為了讓查詢跟索引內容相同
stemmed_query = nltk.stem.PorterStemmer().stem(query).split()
results = query_tfidf(stemmed_query, invindex)
for rank, res in enumerate(results):
# e.g 排名 1 DOCID 176 SCORE 0.426 內容 South Korea rose 1% in February from a year earlier, the
print("排名 {:2d} DOCID {:8d} SCORE {:.3f} 內容 {:}".format(rank+1,res[0],res[1],raw_docs[res[0]][:75]))
今天的Jupyter Notebook延續昨天的檔案,放在這裡。
TF-IDF本身是個很簡潔而直觀的公式,不過在實務上多數會選擇使用TF-IDF的改良版:BM25。核心不變,但BM25增加了一些參數以達到Smoothing平滑的效果。
請問在 詞頻(TF) 解釋段落中的這一部份
例如某篇文章總共有20個字詞,如果我們想知道
rock在這個文章中的詞頻,而rock總共出現了3次,那麼詞頻就會是 (3/100 = 0.03)。
詞頻結果為什麼是 3/100 = 0.03 呢?
不確定那時候為什麼會寫成20,不過應該是100個字詞哈哈哈
謝謝你!

